“목소리 복제해서 AI스피커로”...네이버, ‘화자 인식' 도입 예정
화자 인식 적용한 AI스피커 하반기 출시
개인화 음성합성, 자연어 처리 등 소개
화자 인식 적용한 AI스피커, 하반기 출시
개인화 음성합성, 자연어 처리 등 소개
네이버가 조만간 원하는 사람의 목소리로 말하고, 사용자별 음성을 구분하는 인공지능(AI) 스피커를 출시한다. AI스피커에서 기계음이 아닌 연예인 목소리를 들을 수 있고, 또 가족 구성원마다 다른 목소리로도 응답하는 것이 가능해질 전망이다.
◆ “음성인식 기술 수준, 서당개 풍월 읇는 것보단 뛰어나”
네이버는 4일 서울 서초동 'D2스타트업팩토리'에서 열린 네이버 테크포럼을 열고, 자사 AI 스피커에 쓰이는 음성인식, 자연어 처리, 음성합성 기술에 대해 설명했다. 네이버는 현재 화자인식과 음성 합성 기술 고도화에 주력하고 있다.
기존에는 텍스트 위주 였다면, 더욱 자연스러운 AI 스피커 인식률을 위해 실제 대화에 기반한 인식 기술을 끌어올리고 있다. AI 음성인식 수준이 올라가면 사용자 역시 편하게 말한다. 우리가 친구와 대화를 나눌 때 의도적으로 발음이나 어조를 신경쓰지 않고 생각나는대로 말하기 때문에 정확도 역시 낮아지는 것이다.
네이버는 목표는 AI스피커가 이같은 조건에서도 대화체를 인식하고, 사용자와 대화를 이어나가는 것이다. 인식률을 높이기 위해 스피커의 음악 등 주변 소리는 걷어내고 사용자 목소리를 듣는 ‘어쿠스틱 에코 캔슬레이션(ACE)' 기술이나, 공간 배치와 거리 등 음성인식 정확도를 시뮬레이션하는 ’버추얼 룸 시뮬레이터‘ 등을 활용하고 있다.
또 동일한 뜻이라도 수십가지의 표현을 할 수 있는데 이 때 감탄사, 실수로 잘못 나온 말, 유사어 등을 구별하는것도 ‘자연어 처리(NLP)' 단계에서 진행한다. 예를 들면 “시그널 틀어줘”라고 말하면 게임, 음악 등 각 분야별로 시그널이라는 제목의 콘텐츠가 있지만 스피커라는 조건을 인지해 노래 시그널을 틀어줄 수 있다.
그렇다면 네이버의 현재 음성인식 기술 수준은 어느 정도일까. 강인호 자연어 처리 기술 리더는 “여러분들이 흔히 얘기하는 내용이나 주제에 대해서는 서당개 삼년이면 풍월을 읊는 그 수준보다는 똑똑하다”며 “단어를 던지면 친구랑 얘기할 수 있는 수준”이라고 설명했다. ‘지민’이라는 이름을 주면 인기 아이돌 그룹 AOA의 ‘지민’인지 방탄소년단(BTS)의 ‘지민’인지 구별은 할 수 있다는 것이다.
다만 생소한 주제나 전문지식에 대해서는 여전히 부족한 인식률을 보인다는 설명이다.
◆ 화자인식 도입되면?...“음성합성 악용, 걱정 일러”
네이버는 이같은 자사의 음성인식 기술을 적용시킨 AI스피커를 하반기 선보인다. 특히 사용자의 목소리를 구별하는 ‘화자 인식’ 기술이 탑재된다. 김재민 네이버 클로바 보이스 리더는 “일본에서 데모 버전을 공개한 만큼 빠른 시일내에 서비스 할 계획”이라고 답했다.
기계목소리가 아닌 엄마나 아빠 내가 좋아하는 유명인 목소리를 AI스피커에 등록시켜 사용할 수 있는 것이다. 라인메시지를 읽어준다거나, 엄마 목소리로 아이에게 동화책을 읽어주는 것도 가능할 전망이다. 또 네이버는 화자인식 기술을 상품 주문, 결제에도 도입할 계획이다.
네이버는 효율적인 화자 인식을 위해 엄청난 빅데이터의 용량을 단 시간에 처리하는 기술도 개발했다. 딥러닝 스피티 시네틱 시스템(DTS)를 통해 보통 100시간 정도 걸리는 녹음작업을 4시간까지 줄였다. 구글과 견줘도 월등한 기술이라는 강조다. 구글 역시 네이버와 동일한 화자인식 서비스를 개발중이다.
네이버는 더불어 음성 합성 기술도 개발중이다. 자연스러운 AI스피커의 목소리를 위해 목소리를 복제하는 것이다. 구글 ‘듀플렉스’처럼 원음에 가까운 합성음이 나올 수 있도록 하는 것이 핵심이다. DTS 기술 덕분에 4시간 정도면 인기 가수 목소리를 합성할 수 있다.
단 일각에서 우려되는 목소리 복제 범죄 가능성에 대해서는 아직 이르다고 전망했다. 김재민 음성합성 기술 리더는 “음성을 합성할 때 배경음을 등 부가정보를 넣거나, 합성음이라고 사전에 알려주는 방법이 있다”면서도 “합성음과 사람 목소리의 차이가 많이 나기 때문에 걱정할 단계는 아니다”고 말했다.
©(주) 데일리안 무단전재 및 재배포 금지





 왼쪽부터 강인호 자연어처리 기술 리더, 한익상 네이버 음성인식 기술 리더, 김재민 음성합성 기술 리더. ⓒ 데일리안 이호연 기자
왼쪽부터 강인호 자연어처리 기술 리더, 한익상 네이버 음성인식 기술 리더, 김재민 음성합성 기술 리더. ⓒ 데일리안 이호연 기자
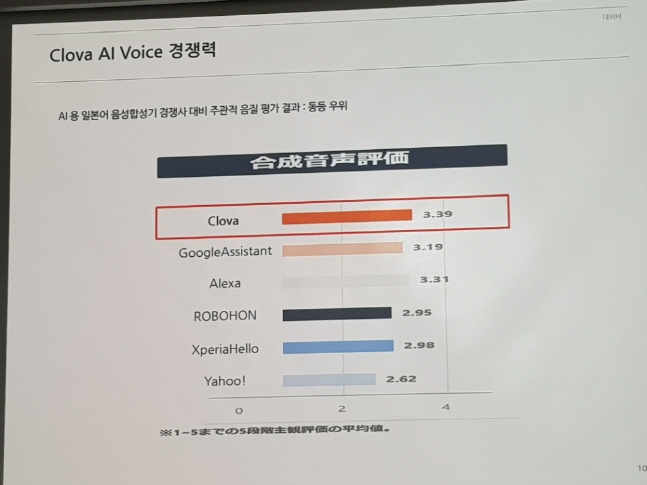 네이버 '클로바 AI 보이스' 기술 수준. ⓒ 데일리안 이호연 기자
네이버 '클로바 AI 보이스' 기술 수준. ⓒ 데일리안 이호연 기자








